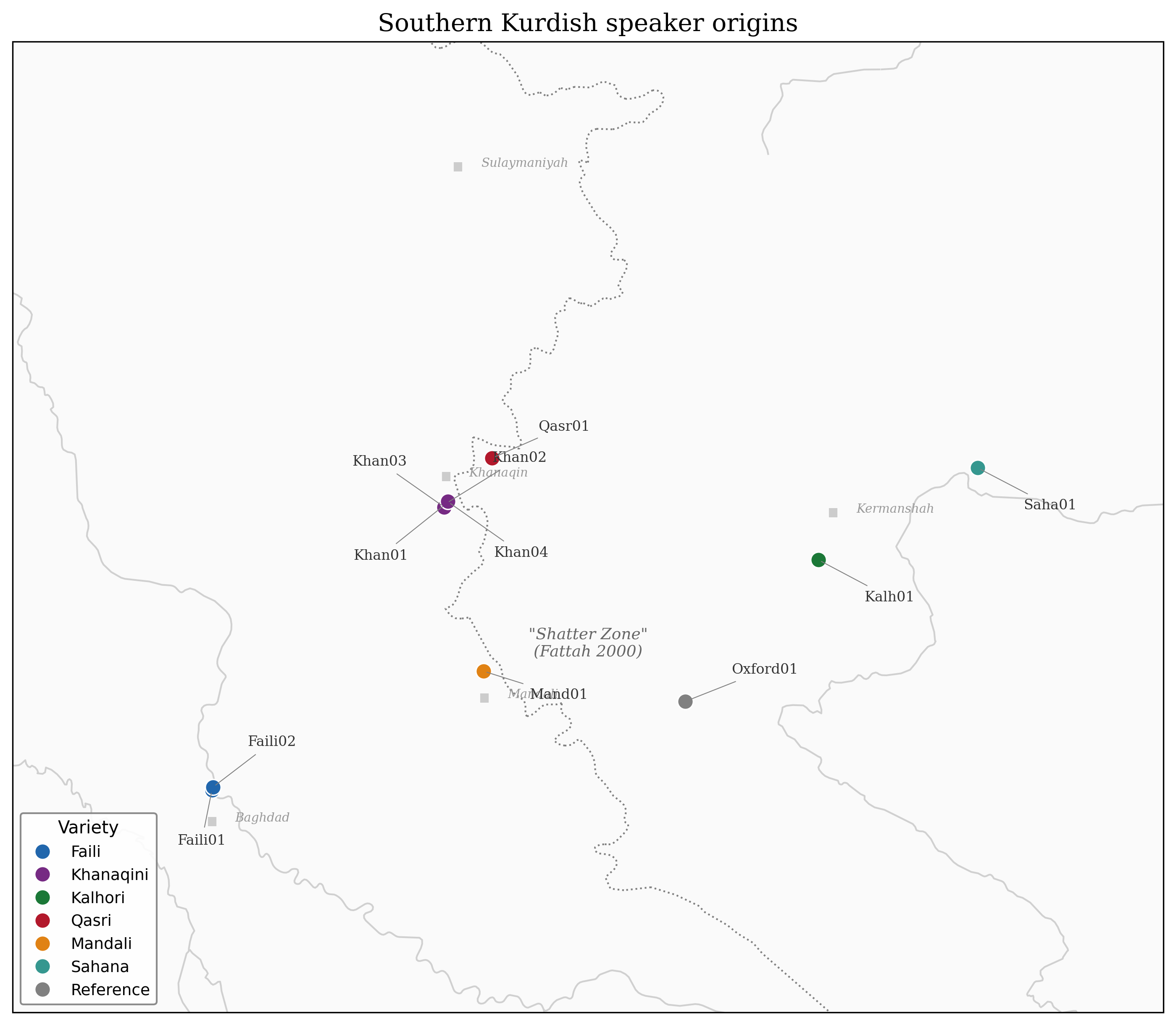
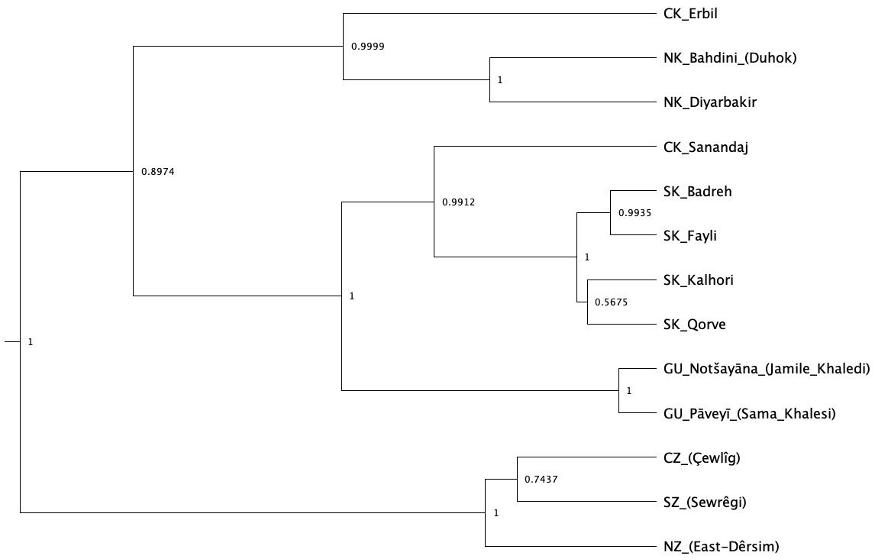
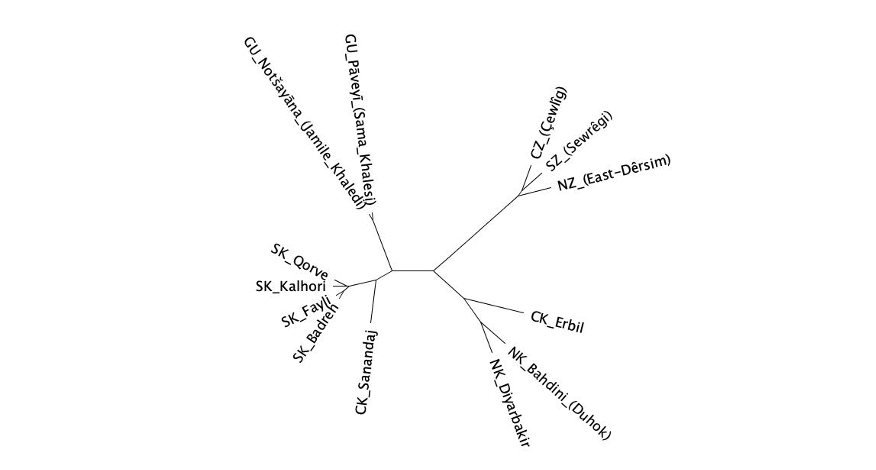
The classification puzzle
Sixty years.
No consensus.
- 11 speakers, 6 varieties — Faili, Kalhori, Khanaqini, Qasri, Mandali, Sahana
- Iraq–Iran borderlands — a shatter zone of tribal, political, and contact pressure
- MacKenzie (1961), Fattah (2000), Belelli (2019), Mohammadirad — no agreement
- Isoglosses cross-cut each other; no clean tree by traditional methods